浏览器的主要功能是将用户选择得web资源呈现出来,从服务器请求资源,并将其显示在浏览器窗口中,资源格式包括html、PDF、image、svg以及其他格式。用户通过URI(统一资源标识符)来指定所请求资源的位置。
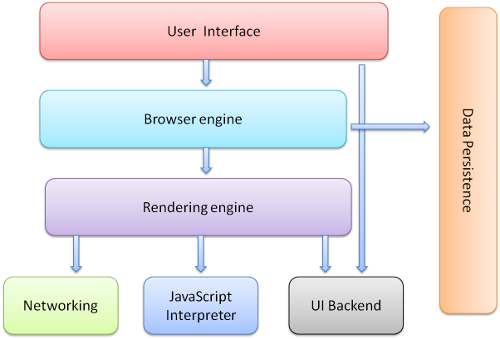
浏览器的主要构成
- 用户界面——包括地址栏、后退/前进按钮/书签目录等,除了用来显示请求页面的主窗口外的其他部分
- 浏览器引擎——可以在用户界面和渲染引擎之间传送指令或在客户端本地缓存中读写数据等,(用来查询及操作渲染引擎的接口)
- 渲染引擎——用来显示请求的内容,例如html,它负责解析html及css,并将解析后的结果显示出来。我们常说的浏览器内核主要指的是渲染引擎。
- 网络——用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作
- js解释器——用来解释执行js脚本的模块,比如V8引擎、javascriptCore
- UI后端——用来绘制基本的浏览器窗口内控件,如输入框/按钮/单选按钮等,根据浏览器不同绘制的视觉效果也不同,但是功能都是一样的
- 数据存储——浏览器再硬盘中保存cookie、localStorage等各种数据,可以通过浏览器引擎提供的API进行调用
作为前端开发人员,我们需要重点理解渲染引擎的工作原理,灵活应用数据存储技术,在实际项目开发中会经常涉及到这两个部分,尤其是在做项目性能优化时,理解浏览器渲染引擎的工作原理尤为重要。而其他部分则是由浏览器自行管理的,开发者能控制的地方较少。
需要注意的是,不同于大部分浏览器,Chrome为每个Tab分配了各自的渲染引擎实例,每个Tab就是一个独立的进程。
渲染引擎
渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。
默认情况下,渲染引擎可以显示html、xml文档及图片,它也可以借助插件(一种浏览器扩展)显示其他类型数据,例如使用PDF阅读器插件,可以显示PDF格式。
当然,渲染引擎最主要的用途——显示应用了CSS之后的html及图片。
主流程
渲染引擎通过网络获得所请求文档的内容后的主流程:
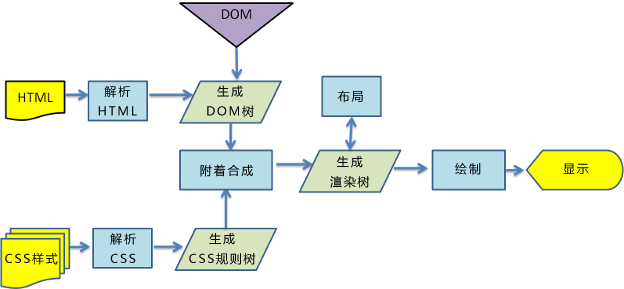
解析html以构建dom树——构建render树——布局render树——绘制render树

解析HTML构建DOM树时渲染引擎会将html文件的便签元素解析成多个dom元素对象节点,并且将这些节点根据父子关系组成一个树结构
同时,css文件被解析成css规则表,然后将每条css规则按照【从右向左】的方式在DOM树上进行逆向匹配,生成一个具有样式规则描述的DOM渲染树。
这些样式信息以及html中的可见性指令将被用来构建另一棵树——render树
render树构建好之后,会执行布局过程,它将确定每个节点在屏幕上的确切坐标。
绘制即是遍历render树,并使用UI后端层绘制每个节点
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
webkit内核工作主流程
解析 Parsing-general
解析一个文档就是把它转换成计算机可以理解和使用的东西。解析的结果通常是表达文档结构的节点树,称为解析树或语法树。
文法 Grammars
解析基于文档依据的语法规则——文档的语言或格式。
解析器——词法解析器
解析分为两个子过程——语法分析和词法分析
词法分析就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合。对于人类语言来说,相当于我们字典中出现的所有单词。
语法分析指对语言应用语法规则。
解析过程是迭代的,具体详情请点击此处
转换 Translation
解析一般在转换中使用——将输入文档转换为另一种格式。例如编译,编译器在将一段源码编译为机器码的时候,先将源码解析为解析树,然后将该树转换为一个机器码文档。
解析器类型 Types of parsers(????????????????????????)
有两种基本的解析器——自顶向下解析以及自底向上解析,
?????????????????????????????

自底向上解析????????????
自动化解析
解析器生成器是一种工具,可以自动生成解析器,只需要指定语言的文法——词汇及语法规则,它就可以生成一个解析器。
webkit使用两个解析生成器——用于创建语法分析器的Flex和创建解析器的Bison。Flex的输入是一个包含了符号定义的正则表达式,Bison的输入是用BNF格式表示的语法规则。
HTML解析器
html解析器的工作是将html标识解析为解析树
非上下文无关文法
由于所有的传统解析方式都不适用于html,html不能简单的用解析所需要的上下文无关文法来定义。
html的正式的格式定义——DTD(Document Type Definition 文档类型定义)——它不是上下文无关文法。html接近于XML,但是比xml更宽容,是一种soft语法。
因为它的宽容使得很难去写一个格式化的文法,所以既不能使用传统的解析器解析,也不能使用xml解析器解析。
DOM(Document Object Model)
输出的树,即解析树,是由DOM元素以及属性节点组成的。DOM和标签基本是一一对应的关系。
解析算法
html不能被一般的自顶向下或者自底向上的解析器所解析
原因是:
- 这门语言本身的宽容性
- 浏览器对一些常见的非法html有容错机制
- 解析过程是往复的,通常源码不会在解析过程中发生改变,但是在html中,脚本标签包含的
document.write可能会添加标签,这说明在解析过程中实际修改了输入,不能使用正则解析技术,浏览器为html定制了专属的解析器。
html5规范中描述了这个解析算法,包括两个阶段——符号化和构建树。
符号化即词法分析的过程,将输入解析为符号,html的符号包括开始标签、结束标签、属性名和属性值。
符号识别器识别出符号后,将其传递给树构建器,并读取下一个字符,一直这样操作直到处理完所有输入。